
Understanding Wikipedia’s Dark Matter: TRANSLATION AND MULTILINGUAL PRACTICE IN THE WORLD’S LARGEST ONLINE ENCYCLOPAEDIA
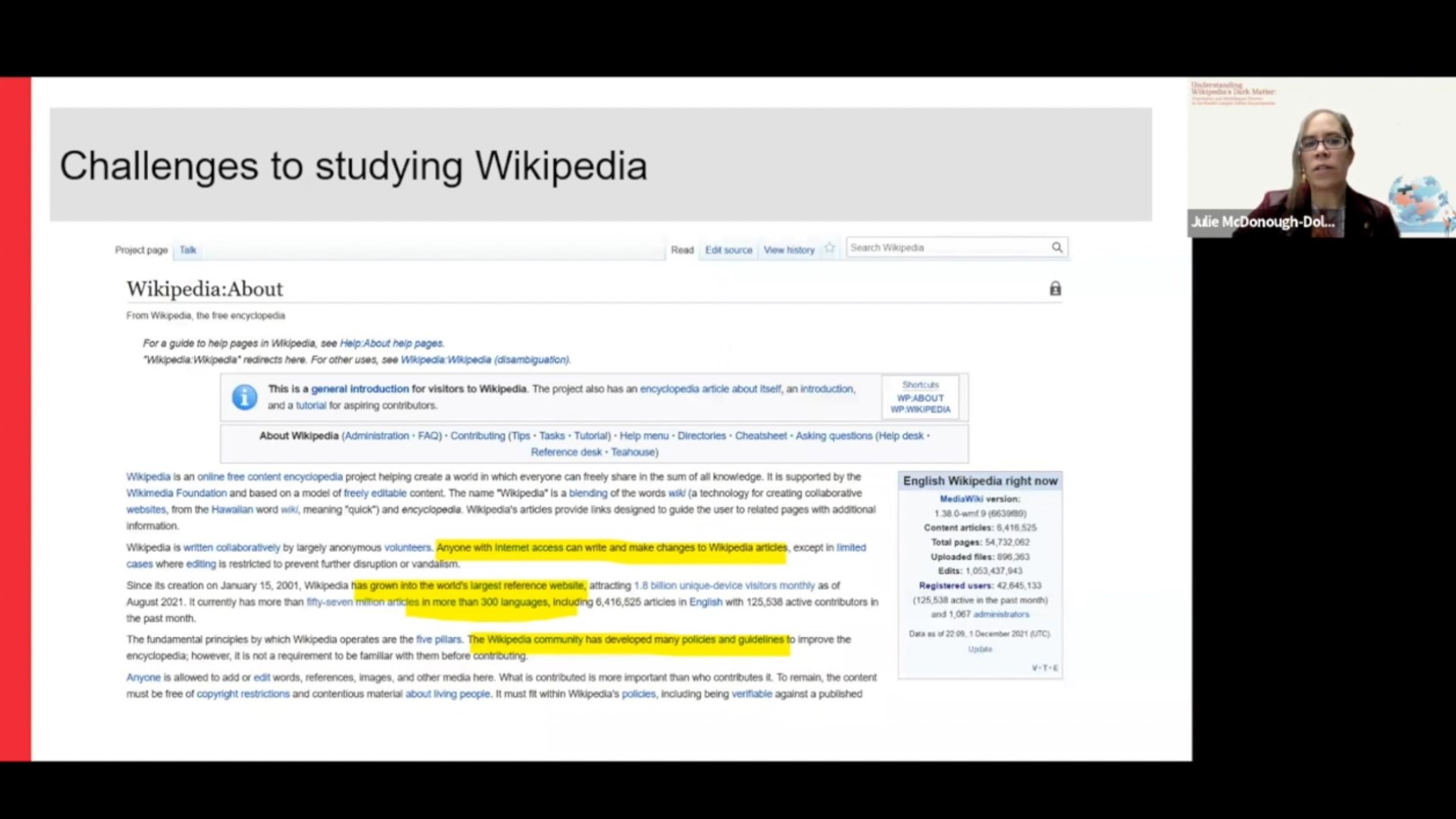
Digital research methods to identify, analyze and visualize conflicts in Wikipedia's translation-related articles
2021 | 68 mins
Corpus-based Wikipedia studies: Theoretical and methodological challenges for translation scholars
2021 | 78 mins
Tales of the "fish in your ear": How does Wikipedia help to shape a public narrative on interpreting?
2021 | 85 mins
Scraping Wikipedia articles
2021 | 36 mins
Cognitive Challenges of Conference Interpreting
2024 | 118 mins
Tom, Dick and Harry as Well as Fido and Puss in Boots are Translators: The Implications of Biosemiotics for Translation Studies
2024 | 86 mins
Translating for the United Nations
2024 | 28 mins
The Long Journey of Renditions
2024 | 25 mins
Working as a Simultaneous Interpreter in the Government of the Hong Kong Special Administrative Region, People's Republic of China
2024 | 36 mins
Community Interpreting in Australia: Policies, Structures, Training, Certification, Industry and Client Needs, and the Profiles of Contemporary Community Interpreters
2024 | 117 mins
Artificial Communication: AI and Interpreting
2023 | 124 mins
My Appointment with Onegin: Charles Johnston, Douglas Hofstadter and Stanley Mitchell
2023 | 60 mins
Artificial Intelligence and Financial Translation
2023 | 121 mins
Conceptualizing Culture, Power, and Ethics in Interpreter-mediated Medical Encounters
2023 | 119 mins